
The Brain Gets Smarter: How Multi-Agent AI Turns a Process Repository into a Living Intelligence System
A follow-up to: " Your Signavio–CALM Integration Is a Pipe. We Built a Brain. https://prod-bpexperts.squarespace.com/newsfeed/2026/3/20/from-pipe-to-brain-rethinking-signaviocalm-integration-with-ai-native-architecture "
A follow-up to: "Your Signavio–CALM Integration Is a Pipe. We Built a Brain."
The Brain Gets Smarter: How Multi-Agent AI Turns a Process Repository into a Living Intelligence System
A follow-up to: "Your Signavio–CALM Integration Is a Pipe. We Built a Brain."
In our previous article, we showed how connecting SAP Signavio and SAP Cloud ALM through a knowledge graph transforms a data pipeline into something that can reason. The brain existed. It could answer questions about what was in scope, where gaps were, and how processes connected to SAP scope items.
The question we kept getting was: what does the brain actually think — and how does it get smarter over time?
This article is the answer.
The problem with a brain that only knows process structure
A knowledge graph of processes, E2E domains, SAP scope items, and capabilities is a powerful foundation. But it answers only one type of question: what is. What processes do we have. What scope items are in scope. What scenarios the reference model defines.
The questions that actually drive value in BPM engagements are different. They are questions like:
Which AI use cases are validated for our Order-to-Cash scenarios, and what economic value do they represent?
If we automate invoice matching with an autonomous AI agent, which compliance obligations apply — and what controls must be built into the process design before we even talk about go-live?
Should we use SAP standard or a best-of-breed solution for financial planning, and where does that decision change if we need sophisticated scenario modelling?
These questions require not just process knowledge, but three additional dimensions: innovation context (what AI use cases exist and what they deliver), compliance knowledge (what regulatory obligations apply to which processes and AI systems), and balanced evaluation (how competing solution options score against each other).
And they require these dimensions to be in genuine tension with each other — argued, scored, and resolved — not averaged away into a diplomatically acceptable middle ground.
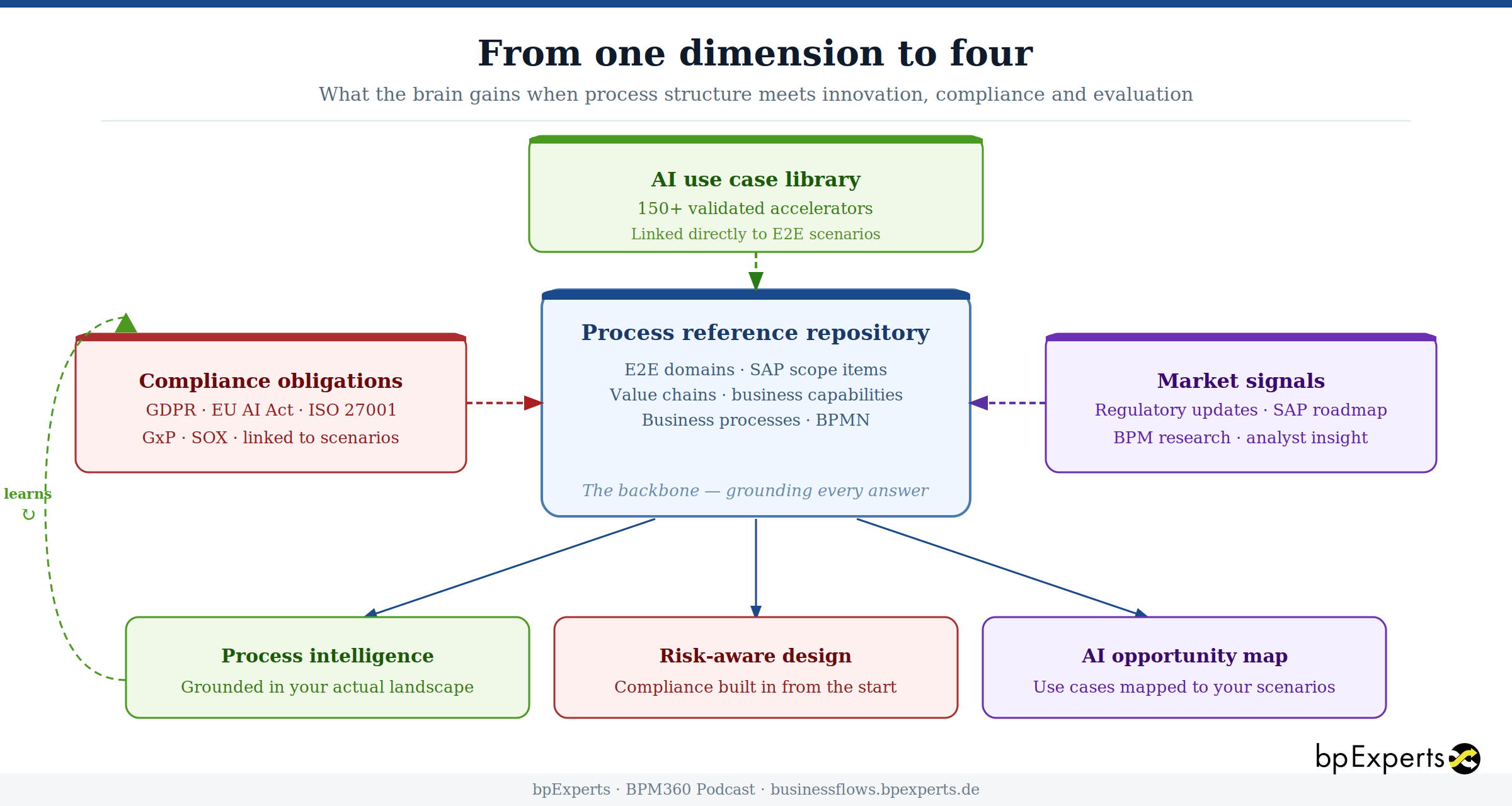
Adding the three dimensions to the brain
The process reference repository remains the backbone. It is what grounds every answer in the structure of your actual process landscape, not in generic best practice.
But now three knowledge streams flow into it continuously.
AI use cases are mapped directly to E2E scenarios. When a process analyst surfaces a specific scenario — say, vendor invoice clearing in the A2R domain — the system already knows which AI accelerators have been validated for that scenario, what their descriptions are, and what transformation they enable. This is not a generic list of AI possibilities. It is a specific, curated set of use cases anchored to your process structure.
Compliance obligations are structured as knowledge nodes, linked to the scenarios they constrain. GDPR Article 22 (automated decision-making) is linked to every scenario where an AI system could make decisions affecting individuals without human review. SOX segregation of duties obligations are linked to every A2R, O2C, and Pl2P financial flow. GxP validation requirements are linked to quality management scenarios. When a scenario is surfaced in a debate, the compliance obligations that apply to it are loaded automatically — not looked up manually, not forgotten.
Market signals — regulatory updates, BPM research, SAP roadmap developments — flow in as additional context that the agents can draw on when the question requires current awareness rather than only structured reference data.
What makes this different from simply having three separate databases is the graph structure. The relationships are explicit. An AI use case is not just "relevant to financial planning" — it is specifically linked via a typed relationship to the E2E scenario it accelerates. A compliance obligation is not just "applicable to AI" — it is linked to the specific AI accelerators it flags, with the penalty range and mandatory controls stored on the obligation node itself. When agents query the graph, they are not doing keyword search. They are traversing a connected structure that encodes what belongs together and why.
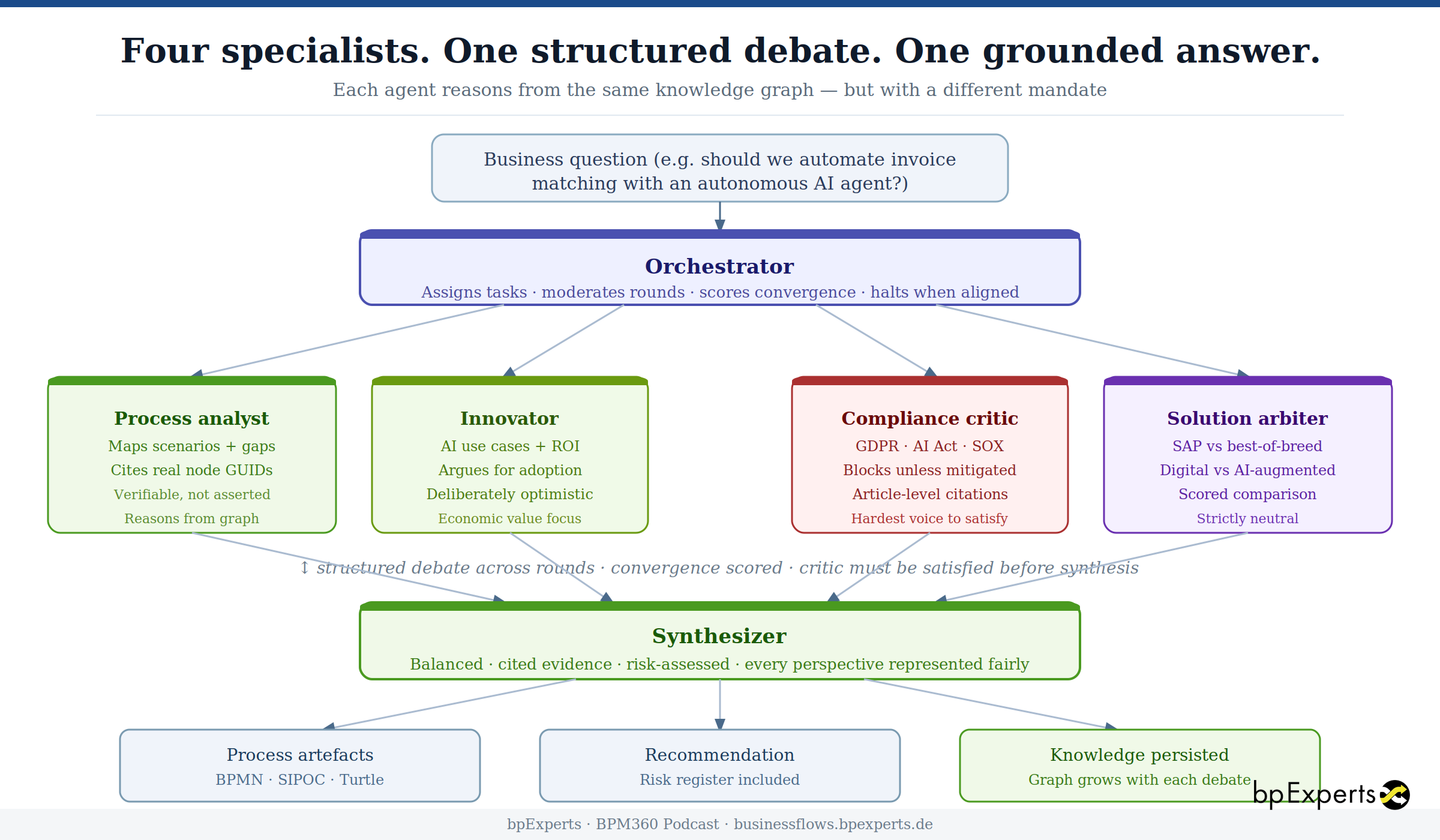
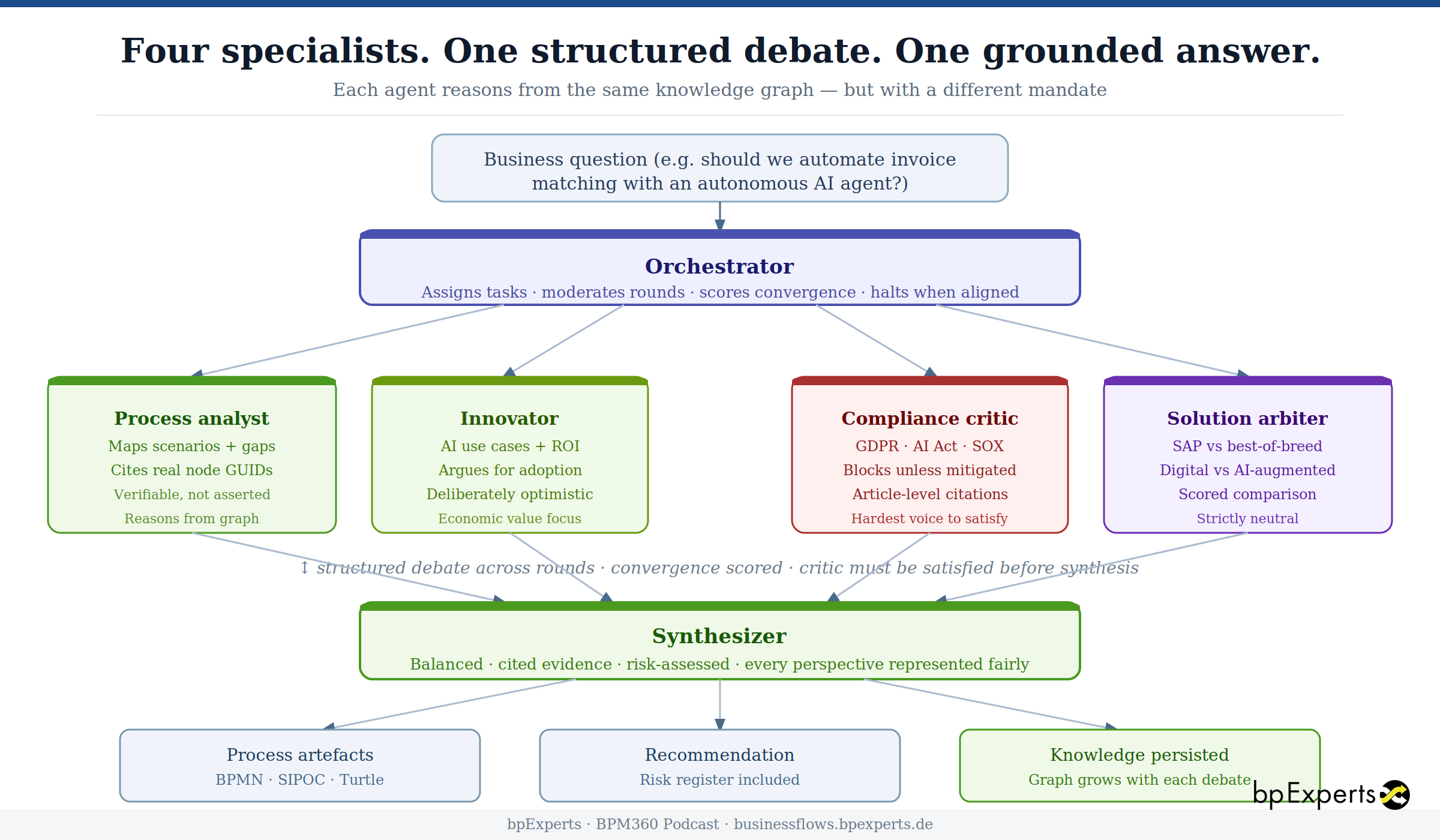
Why multiple agents — and why they debate
The conventional approach to AI-assisted BPM advisory is a single conversation: ask a question, get a response. The response is usually balanced, reasonable, and completely uncommitted. It acknowledges that AI offers opportunities but also has risks. It notes that SAP standard and best-of-breed both have merits. It concludes with a recommendation to assess the specific context.
This is not useful to a practitioner trying to make a real decision.
What a good BPM recommendation actually requires is for competing perspectives to be articulated clearly, placed in genuine tension with each other, and resolved through a structured process — not smoothed away by a single model optimising for diplomatic acceptability.
The multi-agent approach makes each perspective a specialist:
A process analyst maps the question against the reference repository. Which E2E scenarios are implicated? Where are the gaps between current-state coverage and the reference model? What scope items should be in scope but aren't? This agent reasons from graph evidence and cites node IDs — its findings are verifiable, not asserted.
An innovator evaluates the economic opportunity. Which AI accelerators are mapped to the implicated scenarios? What is the case for digitalization and AI-augmentation? This agent argues for adoption when the evidence supports it — it is deliberately optimistic, not artificially neutral.
A compliance critic stress-tests every proposal against the applicable regulatory frameworks — GDPR, EU AI Act, ISO 27001, GxP, SOX. It enters the debate knowing which obligations are linked to the scenarios under discussion, and it argues against adoption unless those obligations can be met. It is the hardest voice to satisfy. That is its value. When the critic flags that an autonomous invoice reconciliation agent triggers GDPR Article 22, SOX segregation of duties, and EU AI Act Article 14 (human oversight requirements), it does so with specific article citations, penalty ranges, and mandatory controls — not with a generic "please consider data protection".
A solution arbiter evaluates the solution options on a scored matrix. SAP standard versus best-of-breed. Digital process automation versus AI-augmented solutions. It scores each on functional fit, implementation effort, TCO, vendor lock-in, and time-to-value — without favouring either axis.
An orchestrator runs the debate. It assigns questions to agents, collects positions, scores convergence, and decides when the positions have sufficiently aligned to produce a synthesis. If the critic has unresolved CRITICAL risks, the debate continues. If all four agents have reached compatible positions, the orchestrator halts and hands the transcript to the synthesizer.
The synthesizer produces a final output that represents every perspective fairly — including unresolved risks, which are flagged prominently rather than buried in a risk register no one reads.
The process designer then converts the agreed synthesis into formal process artefacts: BPMN process structures, SIPOC tables, and Turtle diagrams that already encode the compliance controls that the debate established are mandatory. The human-in-the-loop checkpoint that GDPR Article 22 requires is not added later as an afterthought — it is modelled in the BPMN from the start because the critic made it a precondition of convergence.
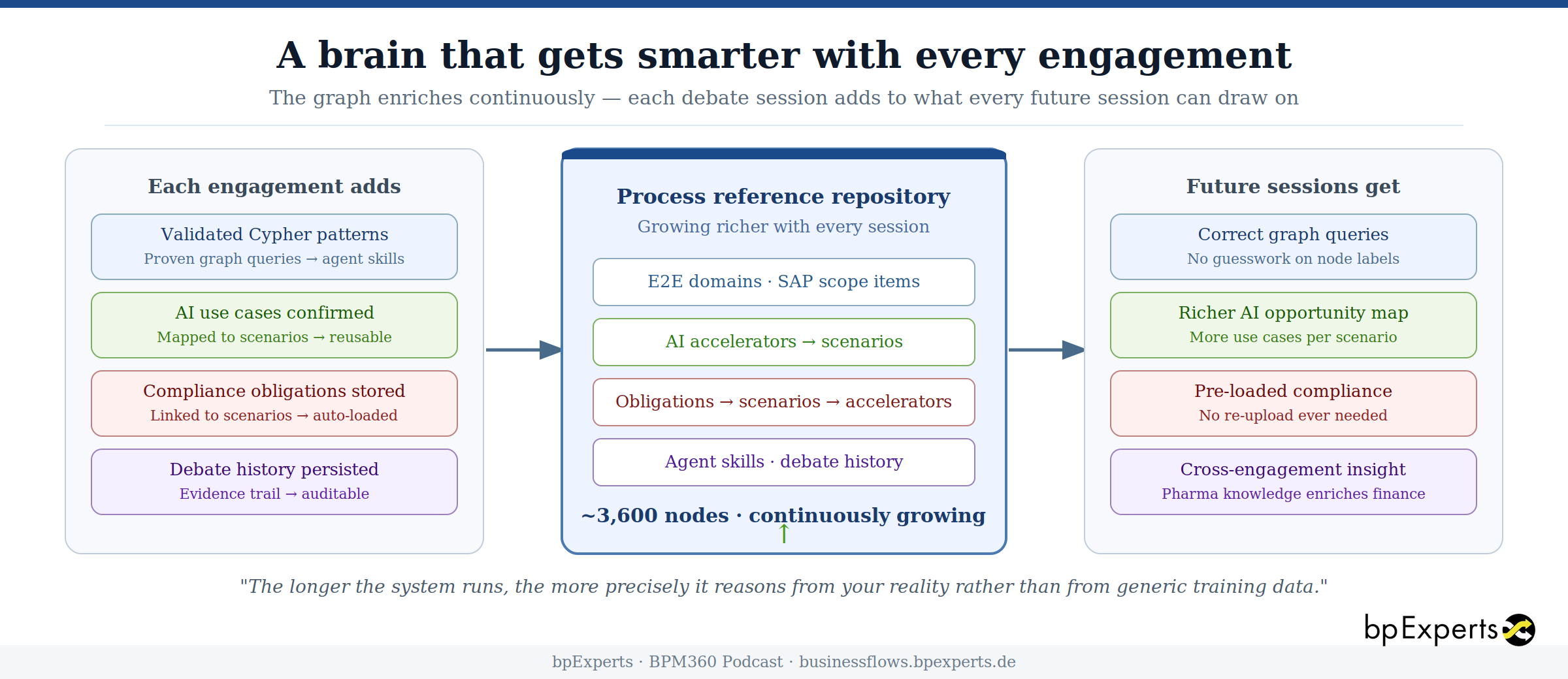
What continuous learning actually means
A system that answers a question once and then forgets everything is not meaningfully intelligent. The brain needs to accumulate.
Every debate session writes back to the graph. The positions each agent took, the evidence nodes they cited, the risks the critic raised — all become part of an auditable history that can be queried, analysed, and learned from.
More importantly, the knowledge the system acquires in one engagement becomes available in the next. A compliance document uploaded for a pharmaceutical client — a GxP SOP, an ISO 27001 policy, a GDPR transfer impact assessment — is stored as a structured knowledge node, linked to the scenarios it constrains, and automatically loaded by the compliance critic in every future debate where those scenarios appear. The document does not need to be re-uploaded. The obligation does not need to be re-explained.
Cypher query patterns that prove reliable in one engagement become encoded as agent skills — loaded into the relevant agent's context at the start of subsequent debates so that it immediately knows the right way to traverse the graph for that type of question.
The reference model itself grows richer with every project. AI use cases validated in one client engagement are linked to scenarios and available for the next. Compliance obligations structured for one industry are automatically scoped to others where the same frameworks apply.
This is not model retraining. The underlying LLM does not change. What changes is the graph — progressively more scenarios mapped, more AI use cases validated, more compliance obligations structured, more proven reasoning patterns encoded. Each engagement benefits from every previous one. The longer the system runs, the more precisely it can ground its answers in the specific structure of your process landscape rather than in generic knowledge from training data.
The shift this creates in practice
For practitioners, the change in conversation is significant.
The starting point shifts from "based on our experience, we recommend..." to "based on your process structure — mapped against the reference model, with the following AI opportunities identified in the graph and the following compliance obligations confirmed — our recommendation is..."
The recommendation may be the same quality of judgement. The foundation is demonstrably different. The process analyst cited twelve node GUIDs. The compliance critic cited specific articles with specific penalty ranges. The solution arbiter produced a scored matrix. Every claim is traceable.
For organisations evaluating AI-assisted BPM advisory, the question to ask is not "how intelligent is the AI?" but "what does it reason from?" A system reasoning from a structured, compliance-linked, AI-enriched process repository is a fundamentally different proposition from a system reasoning from training weights alone — regardless of model size.
The reference repository is the IP. The agents are the reasoning engine. Together they produce something neither can produce alone: BPM intelligence that is grounded in your reality, balanced across competing perspectives, compliant by design, and continuously improving.
The pipe became a brain. Now the brain is learning to think for itself.
At bpExperts we are building and validating this approach in live client engagements. The architecture described here is the result of sustained development — connecting SAP scope items, AI use cases, and regulatory obligations into a knowledge graph that specialist agents reason from in real time. We are happy to explore what this looks like for your organisation.
Follow the BPM360 Podcast for the intersection of process management, AI, and organisational transformation.
]]>